환자 진료기록이나 금융 데이터처럼 개인정보를 한곳에 모으기 어려운 문제를 해결하기 위해 고안된 ‘연합학습(Federated Learning)’이 새로운 발전의 전환점을 찾았다.
KAIST 산업및시스템공학과 박찬영 교수 연구팀이 연합학습의 최대 난제였던 성능저하 문제를 해결할 방법을 제시했다.
연구팀은 연합학습의 고질인 ‘지역 과적합(Local Overfitting)’ 문제를 해결하고, AI 모델의 일반화 성능을 크게 향상시키는 새로운 학습법을 개발했다.
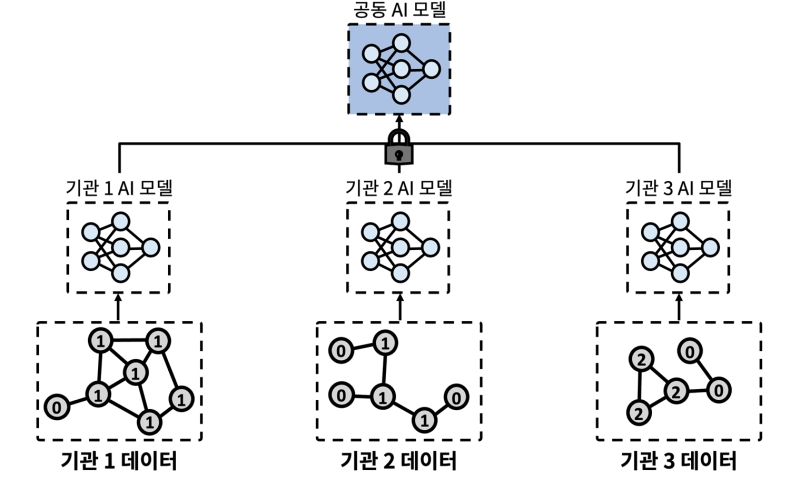
연합학습은 여러 기관이 데이터를 직접 주고받지 않고도 공동으로 AI를 학습할 수 있는 분산형 기술이다.
그러나 이렇게 개발된 공동 AI를 각 기관이 현장 환경에 맞게 추가 학습하는 과정에서 문제가 발생한다.
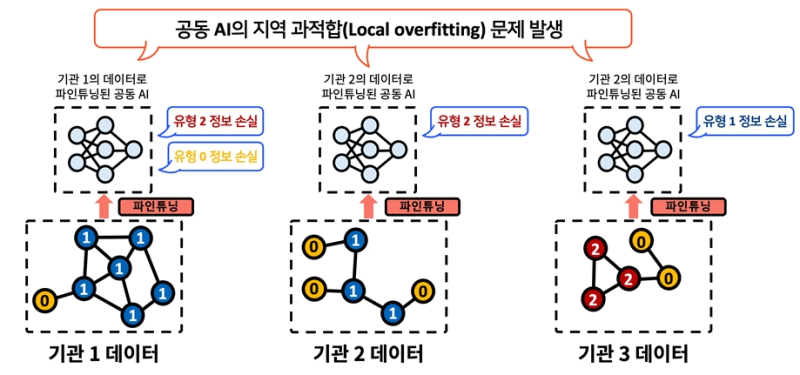
특히 기관별 특화 데이터에 지나치게 적응하면서 공동학습 과정에서 얻은 폭넓은 지식이 희석되고, 새로운 데이터에 대한 적응력이 떨어지는 ‘지역 과적합’ 현상은 연합학습의 확산을 가로막는 핵심 난제다.
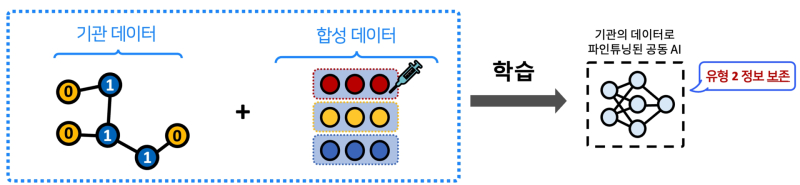
연구팀은 이를 해결하기 위해 개인정보를 포함하지 않고 각 기관 데이터의 핵심 특징만 추출한 ‘합성 데이터’를 도입했다.
또 이를 파인튜닝 과정에서 함께 학습하도록 설계, AI가 특정 기관 데이터에만 치우치지 않고 협업을 통해 얻은 범용 성능을 유지할 수 있도록 했다.
이는 일종의 백신처럼 합성 데이터가 중심을 잡아주는 역할을 하고, 각 기관 AI는 전문성을 강화하는 동시에 새로운 사용자·상품·기관이 등장하는 환경에서도 안정적으로 성능을 발휘토록 한다.
이번 연구는 데이터 프라이버시를 지키면서도 기관별 AI가 전문성과 범용성을 동시에 확보할 수 있는 새로운 길을 열었다는 점에서 의미가 크다.
특히 병원 간 협력진단 AI, 금융기관 간 사기탐지시스템 등 데이터 협업이 필수적이면서 보안이 중요한 분야에서 큰 도움이 될 전망이다.
아울러 소셜네트워크나 온라인 쇼핑처럼 변화가 잦고 불확실성이 높은 환경에서도 안정적인 성능을 유지할 수 있어 실생활에 AI를 안전하게 적용하는 기반을 마련했다.
박 교수는 “이번 연구는 데이터를 직접 공유하지 않고도 각 기관의 AI가 전문성과 범용성을 동시에 보장할 수 있는 방법을 제시한다”며 “의료와 금융뿐 아니라 다양한 산업에서 협력형 AI 활용을 촉진할 수 있을 것”이라고 강조했다.
한편, 이번 연구는 KAIST 데이터사이언스대학원 김성원 박사과정이 제1저자로 수행했고, 연구결과는 지난 4월 싱가포르에서 열린 국제 AI 학술대회 ‘국제표현학습학회(ICLR) 2025’에서 상위 1.8%만 선정되는 구두발표 대상으로 채택됐다.
(논문명 : Subgraph Federated Learning for Local Generalization” (DOI: 10.48550/arXiv.2503.03995))